


#10: The Ultimate Commit
From Junior to CTO Weekly Thoughts

Developers around the world commit changes every day. Does that mean this small part of every development process might have a big impact? Make history cleaner, auto-version artifacts, and simplify code reviews of complex features? In this issue, I will collect principles behind the ultimate commit to help you improve your development process and drastically reduce the complexity of collaborative development. Different version control systems exist, but these thoughts are git-based and not validated against other VCSs.
Motivation
It must benefit us if we apply some effort to make something perfect. If we improve our approach to commit, we must utilize these results. Otherwise, it doesn’t make sense. What utility might we achieve?
Simplified Code Review
Program comprehension takes at least half of work time. Will developers be happier and more productive if code review might pass faster and smoother? We could add a bit more effort on every commit instead of huge efforts on code review. Eventually, the code reviewer doesn’t get hurt by this routine activity and keeps being motivated.
More Practical Code Review
Some well-known research papers say that after 200-400 LOC bug detection density is decreasing dramatically. At the same time, keeping features within such a hard limit is impossible. There should be something more atomic. Randomly reviewed files without a limited scope, mixed refactorings, and feature code might make your code review useless. A more structured approach makes the reviewer more attentive, which helps to find more problems early and saves the team’s time in total.
Change History Analysis
Code must be self-documented with clear variable names that explain what is inside and accurate method names that do not force you to look inside because it is obvious from the method name. That still makes sense to write comments for not obvious fixes that should not be occasionally reverted, for example, explicitly redefined transitive dependency version. But sometimes, we do not understand why some code was written in a particular way instead of an alternative one, we open history and see… nothing. The only “code review fix” or squashed “XX-1234 My amazing feature” ticket name in summary. History doesn’t really help developers to maintain existing code and this might be improved. The Ultimate Commit should give you more context of every particular change, simplify long-term work, help you in 6 months to return, and introduce some changes with minimal side-effects of missed memory pieces.
Inferred Versioning & Change Notes
The meaning of every change must impact, this is a consistent log of code mutations that should help you to automate versioning. Because a set of commits is a set of changes, we might leverage it. I don’t call it “Release Notes” but rather “Change Notes” because developers help themself when they write commit messages, they don’t think about an end user who might read notes inferred from commits, but at the same time, other developers might be interested in what happened.
We clarified what might be improved with “the Ultimate Commit” so let’s try to make obvious properties of one.
Critical Properties of the Ultimate Commit
Small
Keeping complex structures in mind during code review and history analysis is challenging. Small limited changes are much simpler to understand. Just imagine that you review refactoring results and business code separately. Eventually, it is the same code but reviewing pieces separately, you can quickly look through refactorings or style changes and deeply review business ones that will impact your ability as a reviewer to focus on things that matter and keep high bug detection density.
Readable
This is obvious nowadays, but I must mention that the readability of commit messages directly impacts history analysis and program comprehension activities. If you save 1 minute instead of properly formulating a commit message today, this will chase you while the entire project lifetime until you leave the company.
Expressive
I often saw commits with the summary like “fix code review comments”, sometimes even repeated many times. These commits have meaningless summary because they do not explain why (even what) changes were introduced. You might object to me: but changes were introduced because the code reviewer added a comment. This is one of the most popular mistakes I’ve seen. Code Review is a tool for feedback but not a cause. The key task you solve on code review is highlighting different issues. Emphasize issues early to fix them before the root cause is merged. Expressive commit messages help you to formulate and check that you properly understand the motivation behind the comment. Is this just a style issue or a performance bug?
Normalized
There is no need to duplicate information. A summary of the Ultimate Commit should give you more information than you read from the inside code. For example, “add if statement” repeats the content but “handle a corner case” explains why these changes are needed.
Structured
There might be a few types of logical changes, so if we define the domain model, we could build automation for versioning, for example:
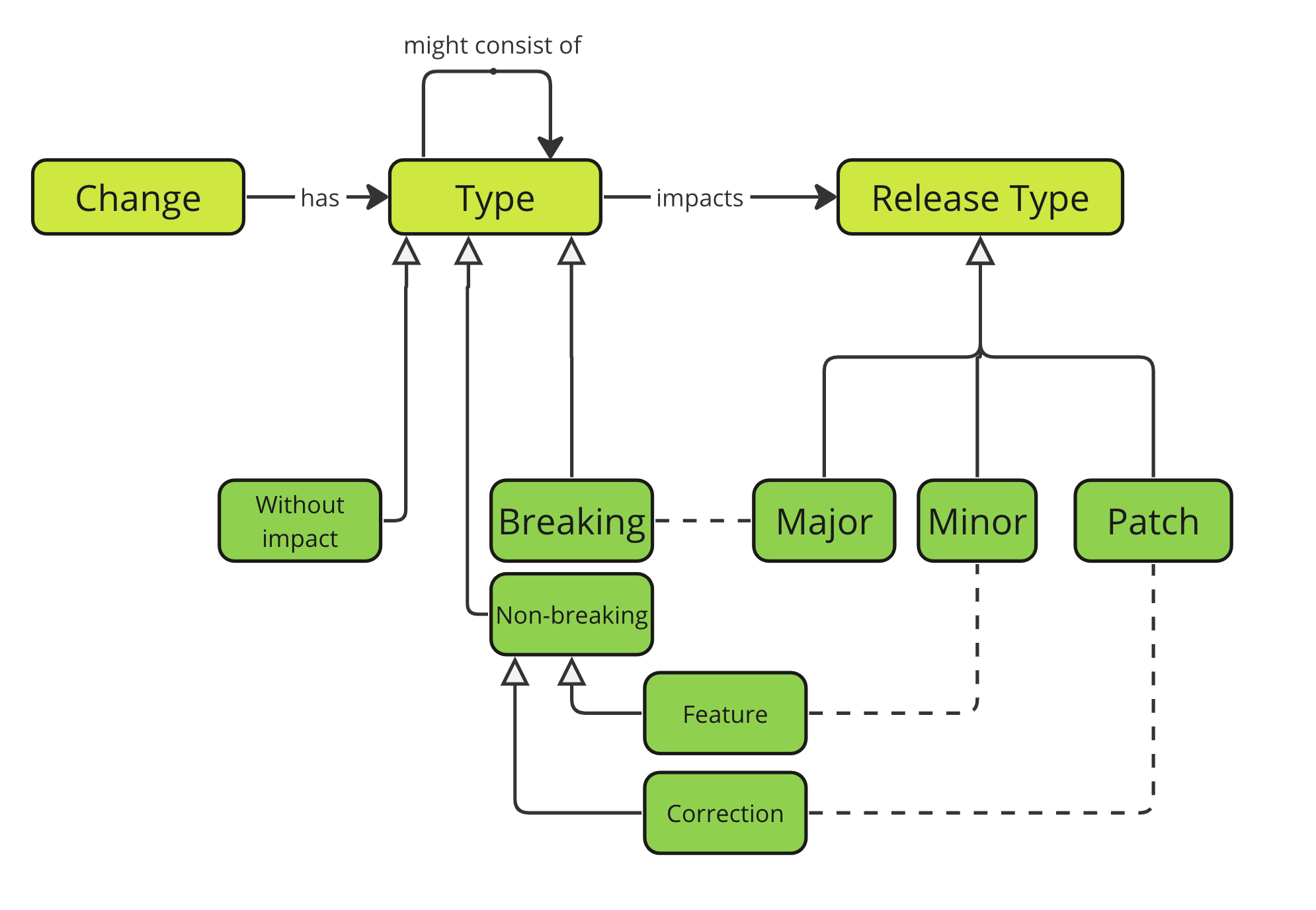
Completed
Committing does not correlate with time, there is no sense to commit every hour or by the end of the day. At the same time, if a change takes more time than your development session or consists of a few changes, you could definitely decompose it. For example, “introduce REST API with stubs under the hood”, “improve resilience with retries for network calls”.
Unified
This might be inefficient to scan some changes by eyes formulated in a passive voice, and others in an active one. Some have information about the initial branch/task, others do not, or this information is added differently.
There should be one standard for every particular commit.
Small, Readable, Expressive, Normalized, Structured, Completed, and Unified. WOW! A lot of properties to satisfy, some of them fully on developer’s shoulders, but others might be controlled independently.
Practices
Conventional Commits
I hope that some of you who already aware of Conventional Commits are recognized that this specification covers the major part of the Ultimate Commit properties. For others, let me explain what it is.
According to the site:
The Conventional Commits specification is a lightweight convention on top of commit messages. It provides an easy set of rules for creating an explicit commit history; which makes it easier to write automated tools on top of. This convention dovetails with SemVer, by describing the features, fixes, and breaking changes made in commit messages.
If a team follows the convention, their commits get the following properties of the Ultimate Commit: small (atomic), structured, completed, and partially unified. Conventional Commits propose many standard types of commits, such as: feat, fix, chore, refactor, docs, style, test, perf (performance), ci, build, revert.
Active voice
Usually, there is an intention to write a commit summary in a passive voice, for example, “user API was introduced”. The problem with this approach is that passive voice is more complex to read because verbs might drastically change from their infinitive form; otherwise, the infinitive form in the present tense makes it simpler. Another motivation is that commit messages will be unified with Merge commits which start from “Merge …”
This practice helps to unify and improve the readability of commits.
Stop squashing
If you start with conventional commits, you must stop squashing of your commits. Now your history has been filled with information you might use, do not lose it.
Commits in history become readable and expressive. They are small, unified, and structured so you can easily understand why some changes were introduced.
A branch name is a ticket code and placed commit message’s footer
Identifying branches via ticket code makes everything simpler. First of all, you don’t need to think about the branch name at all. Secondly, you might add a branch name to the footer of a conventional commit, and if later you want to find all commits related to ticket XYZ-1234 you just search this code in the git history. If the branch were named after the ticket, you would save a lot of time.
It is obvious if you wanted to have exclusions from this rule, sometimes you can but keep in mind that it breaks your development traceability.
What is the best? Branch name addition is easy to automate but amend commits might be tricky.
“Why” instead of “What”
Your commit diff already explains what was changed. You could add more information with your commit message to explain “why”. Use commit history as a chat for communication with new developers who do not understand why a particular line was added so they will read it and not bother you repeatedly. I gave a few examples above.
Tools
Creation
IDE plugins and command line tools might help you to structurize your messages according to specifications.
Git Hooks might add a branch name to the end of every commit. There are several ways to implement git hooks, from manual git config update to build system plugin usage (example for gradle, example for frontend guys).
Validation
IDE plugins also might help you to validate your commit messages.
Git Hooks can help to test commit messages against specifications and other requirements.
Git Server Hooks help to protect from occasionally violated rules.
Version Generation
Semantic Release is a great tool to compute the next semantic version of your artifact and publish it to git server. Commitizen is also a popular one.
The most part of conventional commit-based tools is mentioned here.
Conclusion
The Ultimate Commits are not perfect because they require some effort, but eventually, you improve your code review, code comprehension, and, I’m not afraid to say, the culture of your development.
In one week, we will talk about “The Ultimate Artifact”, subscribe not to miss it!